Nel cuore del dibattito sull’intelligenza artificiale, tra entusiasmi e inquietudini, c’è una domanda che ritorna come un mantra sommesso: “Siamo davvero noi a controllare la tecnologia?”
In un mondo dominato da AI pubbliche come ChatGPT, Gemini o Claude, tutte collegate a grandi aziende e infrastrutture cloud, una piattaforma come LM Studio si presenta come una provocazione potente, ma concreta, e se potessimo avere un’intelligenza artificiale tutta nostra, offline, su misura, che non spia e non limita ciò che può essere chiesto o detto?
Benvenuti in LM Studio (https://lmstudio.ai/), lo spazio digitale in cui l’AI diventa uno strumento personale, non una scatola nera commerciale.
Che cos’è LM Studio?
LM Studio è una piattaforma desktop che consente a chiunque di scaricare, gestire e utilizzare modelli linguistici avanzati direttamente sul proprio computer. Non si tratta di un semplice front-end o di un’estensione di ChatGPT, ma di una vera e propria officina locale per AI open-source.
Offre un’interfaccia intuitiva, compatibilità con decine di modelli (Mistral, LLaMA, Phi, Zephyr, Mixtral e altri), la possibilità di operare offline e soprattutto un grado di personalizzazione e controllo che le AI pubbliche non possono e non vogliono offrire. Vediamo le differenze tra una AI installata in locale e una AI pubblica.
| AI pubbliche | LM Studio |
|---|---|
| Funzionano in cloud | Funziona offline |
| Raccolgono e processano dati in remoto | I dati restano sul dispositivo |
| I modelli sono chiusi, spesso censurati | I modelli sono open-source e personalizzabili |
| Dipendenza da abbonamenti mensili | È gratuito o a costi molto contenuti |
| Limitazioni nei prompt “sensibili” | Libertà di esplorazione senza filtri aziendali |
Privacy, dati e modelli personalizzati
In un contesto in cui anche una semplice chat può essere analizzata, archiviata e monetizzata, LM Studio rappresenta una zona franca. Non avremo nessuna trasmissione di dati sensibili a server esterni, potremo addestrare o far il fine-tuning di modelli su dataset locali ed avere il controllo totale su memoria, cronologia, output e input. Questo significa che un ricercatore, uno sviluppatore o anche un semplice utente può creare un modello cucito sui propri contenuti, senza temere fughe di dati o filtraggi ideologici.
Un aspetto spesso sottovalutato delle AI pubbliche è il filtro sistemico applicato ai contenuti considerati “sensibili”.
Sebbene utile per evitare abusi, questo approccio porta con sé il rischio di una censura algoritmica, dove ciò che è “consentito” o “appropriato” viene deciso da aziende private. LM Studio, permettendo l’uso di modelli non censurati, apre la strada a un’intelligenza artificiale che può trattare argomenti controversi con maggiore apertura.
Consideriamo poi che non è secondario il fatto che LM Studio sia gratuito e che molti modelli siano open-source.
In un’epoca in cui l’intelligenza artificiale sta diventando un servizio a pagamento, l’accesso libero a strumenti potenti è una questione di equità. Con un buon laptop e qualche giga di RAM, oggi si può dialogare con un LM sofisticato, svincolandosi da un’infrastruttura esterna.
Installazione
Come da tradizione, da bravi nerd, non ci limitiamo a osservare: ci piace “sporcarci le mani”, oppure, per dirla in modo ancora più affine alla nostra natura, ci piace smanettare con il software.
La prima operazione, naturalmente, è l’installazione di LM Studio.
Se stiamo utilizzando Windows, il procedimento è semplice, basterà scaricare l’eseguibile dal sito ufficiale e avviarlo. Il programma in sé non è particolarmente pesante, ma attenzione, i modelli linguistici che andremo a scaricare possono essere piuttosto ingombranti.
Consiglio pratico: durante il setup iniziale, scegliamo con cura dove installare la directory dei modelli. Meglio optare per un hard disk capiente, possibilmente un SSD con spazio libero abbondante, per garantire performance elevate e tempi di caricamento rapidi.
Nel momento in cui scrivo, LM Studio propone di default il modello openai/gpt-oss-2b, che richiede circa 12 GB di spazio libero. E questo è solo un modello “leggero”, versioni più potenti possono arrivare a occupare anche 30, 50 o 100 GB.
Una volta completato il download, sarà sufficiente cliccare su “Load Model” per caricarlo in memoria e iniziare a usarlo.
Impostazioni di base
Facciamo un bel respiro profondo e cominciamo ad esplorare l’interfaccia. Non iniziamo a cliccare freneticamente a caso, prendiamoci il tempo necessario per capire in linea di massima com’è organizzata l’interfaccia e com’è stata progettata la user experiance. Iniziamo con un bel “Ciao!” come prompt di inaugurazione.
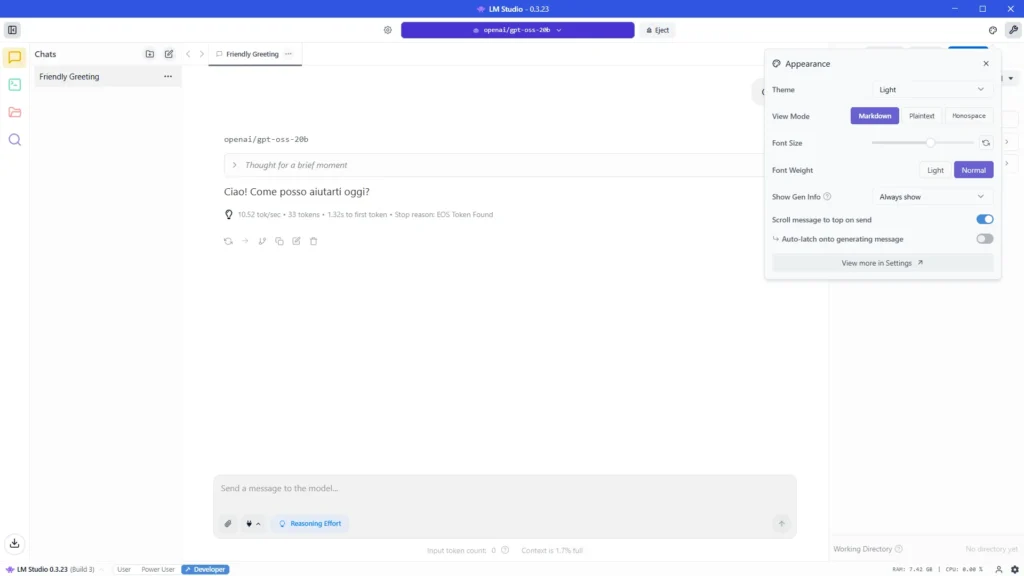
L’interfaccia di LM Studio si presenta con un design pulito e moderno, pensato per soddisfare sia gli utenti esperti che quelli semplicemente curiosi. Consiglio di impostarla in Dark Mode o Classic, una scelta estetica elegante, ma soprattutto funzionale, ideale per ridurre l’affaticamento visivo durante sessioni prolungate.
In basso a sinistra, attiviamo la modalità “Developer”, questo sblocca una serie di impostazioni avanzate che, a prima vista, potrebbero sembrare complesse o criptiche. Non preoccupatevi, non serve comprenderle tutte subito.
Sapere che esistono è già un primo atto di consapevolezza tecnologica, il primo passo verso un rapporto più profondo e autonomo con lo strumento. Portiamo la nostra attenzione alla zona centrale, cominciamo con il comprendere le info elargite da LM Studio.
Nel nome openai/gpt-oss-20b, la parte “20b” è molto significativa e indica la dimensione del modello linguistico. Nel contesto dei modelli linguistici, i parametri sono i numeri che il modello apprende durante l’addestramento e che usa per generare risposte. Più parametri ha un modello, più è teoricamente capace di comprendere, analizzare e generare testo in modo coerente, articolato e preciso. Per farci un’idea leggiamo la tabella di seguito.
| Modello | Parametri |
|---|---|
| GPT-2 | 1.5B |
| GPT-3 | 175B |
| GPT-3.5 (turbo) | ~6-20B (per versioni leggere) |
| GPT-4 | oltre 500B |
| gpt-oss-20b | 20B |
Quindi, gpt-oss-20b è un modello open-source con 20 miliardi di parametri, un buon compromesso tra potenza e usabilità in locale. Di seguito l’hardware minimo consigliato.
| Componente | Requisito minimo |
|---|---|
| RAM di sistema | 16 GB (meglio 32 GB) |
| GPU | 6–8 GB VRAM (es. RTX 3060) |
| CPU | 6 core (es. Ryzen 5, i5) |
| Spazio su disco | 20–30 GB (modello + cache + swap) |
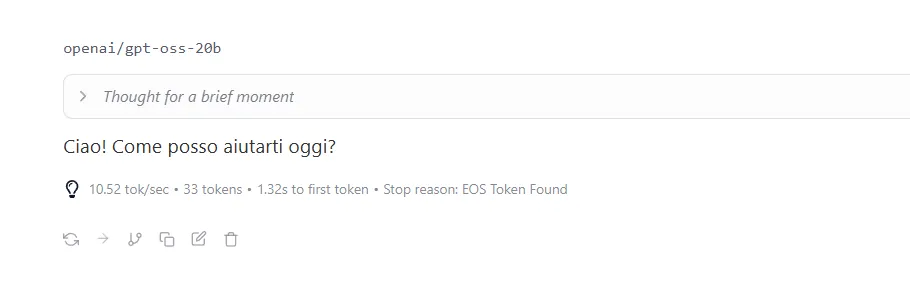
Sotto ogni risposta generata da LM Studio, trovi un piccolo riepilogo tecnico che può sembrare oscuro a prima vista, ma in realtà è molto utile per capire come si sta comportando il modello. Prendiamo ad esempio questa stringa:
“10.52 tok/sec • 33 tokens • 1.32s to first token • Stop reason: EOS Token Found”
Vediamola insieme, passo dopo passo.
La prima parte, “10.52 tok/sec”, ci dice a che velocità il modello ha generato la risposta, in questo caso, ha prodotto circa 10 token al secondo. Un token è un frammento di testo, che può essere una parola, una parte di parola, o anche solo un segno di punteggiatura. Quindi, più alto è questo numero, più velocemente il modello riesce a scrivere.
Poi abbiamo “33 tokens”, ovvero il numero totale di token che compongono la risposta. Questo ci dà un’idea della lunghezza del testo, 33 token equivalgono più o meno a 20-25 parole. Quindi parliamo di una risposta piuttosto breve, composta da un paio di frasi ben costruite.
Il terzo dato, “1.32s to first token”, indica quanto tempo ha impiegato il modello per iniziare a rispondere. In questo caso, circa 1,3 secondi. È un tempo piuttosto buono: significa che il modello ha “pensato” un attimo, ha elaborato il prompt e poi ha cominciato a scrivere.
Infine troviamo la dicitura “Stop reason: EOS Token Found”. Questo significa che la risposta si è fermata naturalmente, perché il modello ha raggiunto un token speciale di fine sequenza (End Of Sequence, o EOS). In parole semplici l’AI ha deciso che la sua risposta era completa e non c’era bisogno di aggiungere altro.
Procediamo cliccando in alto a destra sull’iconcina a forma di chiave inglese.
Spostiamo la nostra attenzione sulla colonna a destra, sul pannello dei preset di LM Studio, uno strumento estremamente potente e flessibile che funziona in modo molto simile ai GPT personalizzati di ChatGPT, ma in versione locale e completamente sotto il nostro controllo.
Tab Context
Nel tab Context, potremo creare e salvare dei preset personalizzati, cioè un insieme di istruzioni predefinite che il modello seguirà ogni volta che inizia una conversazione. Pensiamo ai preset come a delle “personalità” o ruoli operativi che possiamo dare all’AI, proprio come avviene con i GPT personalizzati su ChatGPT (ad esempio: “GPT esperto di cucina”, “GPT insegnante di filosofia”, “GPT psicologo”, ecc.).
Se ad esempio vogliamo creare un esperto di marketing, possiamo inserire qualcosa come: Agisci come un esperto senior di marketing digitale. Fornisci sempre risposte orientate al cliente, con esempi concreti, tono professionale ma accessibile, e consigli utili per aumentare visibilità, conversioni e brand awareness.
Dopo aver scritto il prompt, potremo cliccare su “Save Preset As…” e dare un nome al preset (es. “Esperto Marketing”). Questo ci permetterà di avere modelli personalizzati diversi per ogni ambito, uno per la scrittura creativa, uno per il codice, uno per il business, ecc.
Tab Model
Reasoning Effort
Controlla il livello di sforzo logico che il modello compie per rispondere
Qui è impostato su Low (basso). Questo significa che il modello cercherà di fornire risposte rapide, magari meno articolate, ma più dirette. Se stessimo scrivendo codice semplice o risposte veloci a domande comuni, andrebbe bene. Tuttavia, se vogliamo che l’AI analizzi problemi complessi, suggerisca architetture o gestisca debug dettagliati, potremmo considerare di aumentare il livello a Medium o High, accettando però tempi di risposta più lunghi.
Settings
Questa sezione regola la creatività e coerenza della generazione.
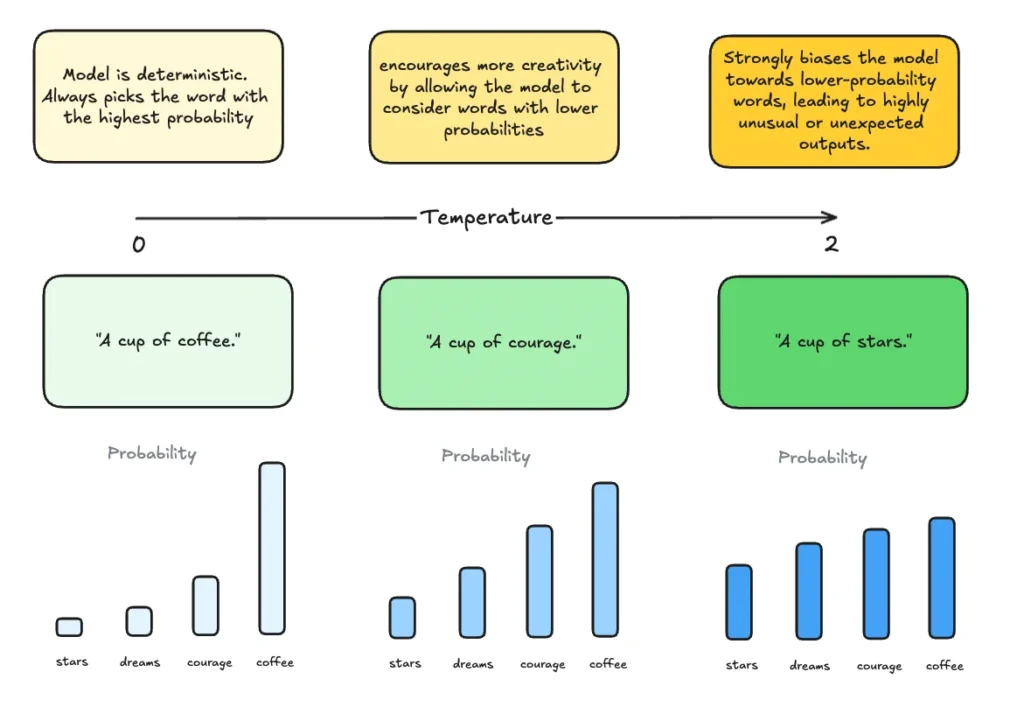
Temperature: 0.8
La temperatura determina quanto vario e creativo sarà il testo prodotto. Valori più bassi (0.2–0.5) generano risposte più prevedibili e schematiche. Valori alti (0.8–1.0) aumentano la varietà, ma con il rischio di minore coerenza. Nel nostro caso, 0.8 è un buon compromesso: stimoleremo risposte creative ma tecnicamente plausibili, perfette per brainstorming, suggerimenti di codice e alternative progettuali.
Limit Response Length: OFF
Lasciando disattivata questa opzione, non poniamo limiti rigidi alla lunghezza delle risposte. Il modello potrà quindi sviluppare spiegazioni più complete, cosa utile per tutorial, spiegazioni passo-passo o refactoring commentati.
Sampling
Controlliamo qui il modo in cui il modello sceglie le parole, influenzando varietà e precisione.
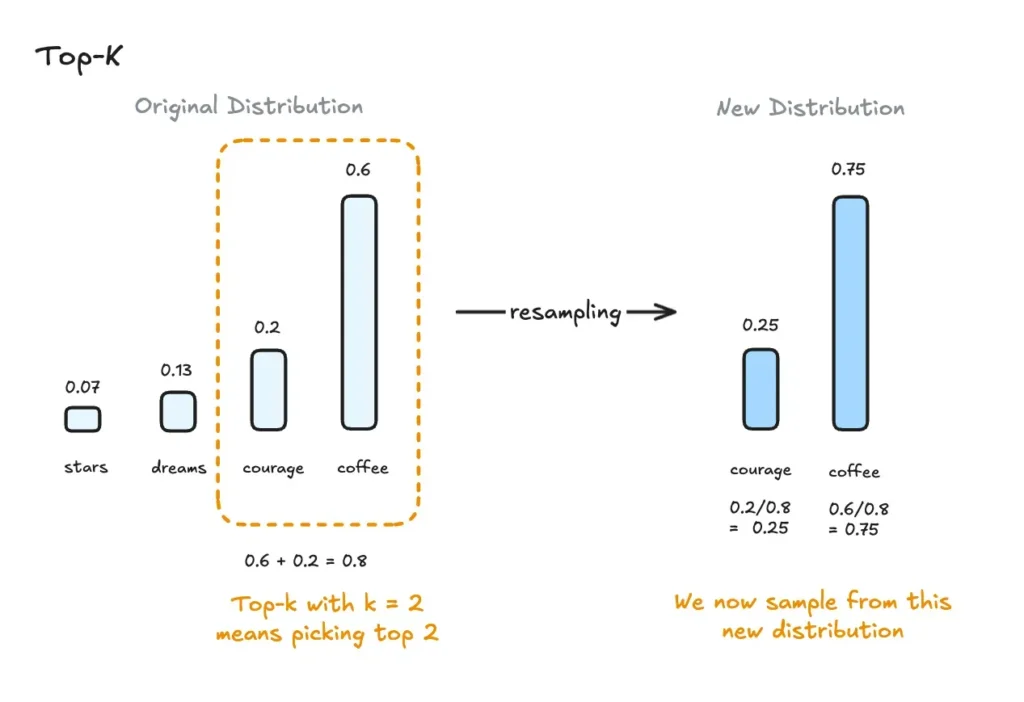
Top K Sampling: 40
Il modello sceglierà tra i 40 token più probabili a ogni passo. Un numero più alto favorisce diversità lessicale ma rischia incoerenze. 40 è una scelta equilibrata per il nostro scopo, evita risposte piatte, ma resta entro un margine sicuro.
Repeat Penalty: 1.1
Il Repeat Penalty serve a penalizzare la ripetizione eccessiva. Con un valore di 1.1, il modello viene disincentivato a riutilizzare troppo spesso le stesse frasi o strutture. Questo è particolarmente utile nelle risposte lunghe o quando si scrive codice, dove la ridondanza può diventare un problema.
A differenza dei parametri presenti nell’API di OpenAI, il Repeat Penalty è un meccanismo tipico degli LLM open source. Funziona come una via di mezzo tra frequency penalty e presence penalty, ma è implementato in maniera diretta e personalizzabile.
Per chiarezza:
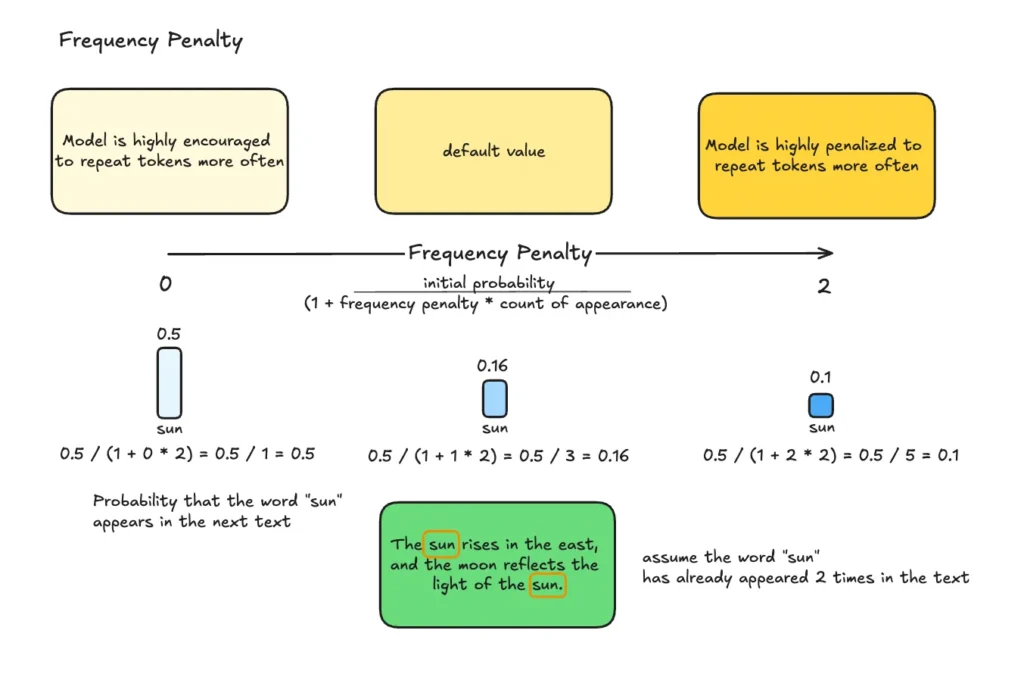
- Frequency penalty (OpenAI API) → penalizza in base a quante volte un token è già stato usato: più è frequente, più la sua probabilità di comparire di nuovo diminuisce.
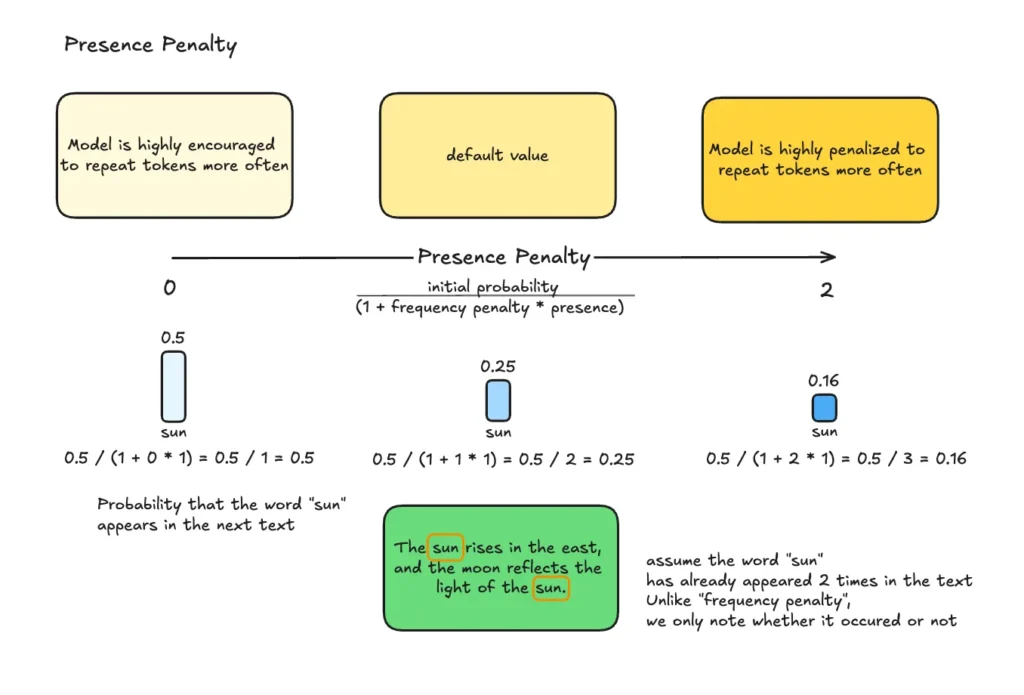
- Presence penalty (OpenAI API) → penalizza la semplice presenza di un token già usato (anche una sola volta), spingendo il modello a introdurre contenuti o argomenti nuovi.
Min P Sampling: 0.05
È una soglia che filtra le opzioni troppo improbabili, scartando quelle con probabilità bassissima.
Così facendo, evitiamo che il modello si lanci in generazioni completamente fuori contesto.
Top P Sampling: 0.8
In alternativa al Top K, il Top P (noto anche come nucleus sampling) considera i token più probabili fino a raggiungere una probabilità cumulativa dell’80%. Anche questo parametro contribuisce a una generazione bilanciata tra coerenza e varietà.
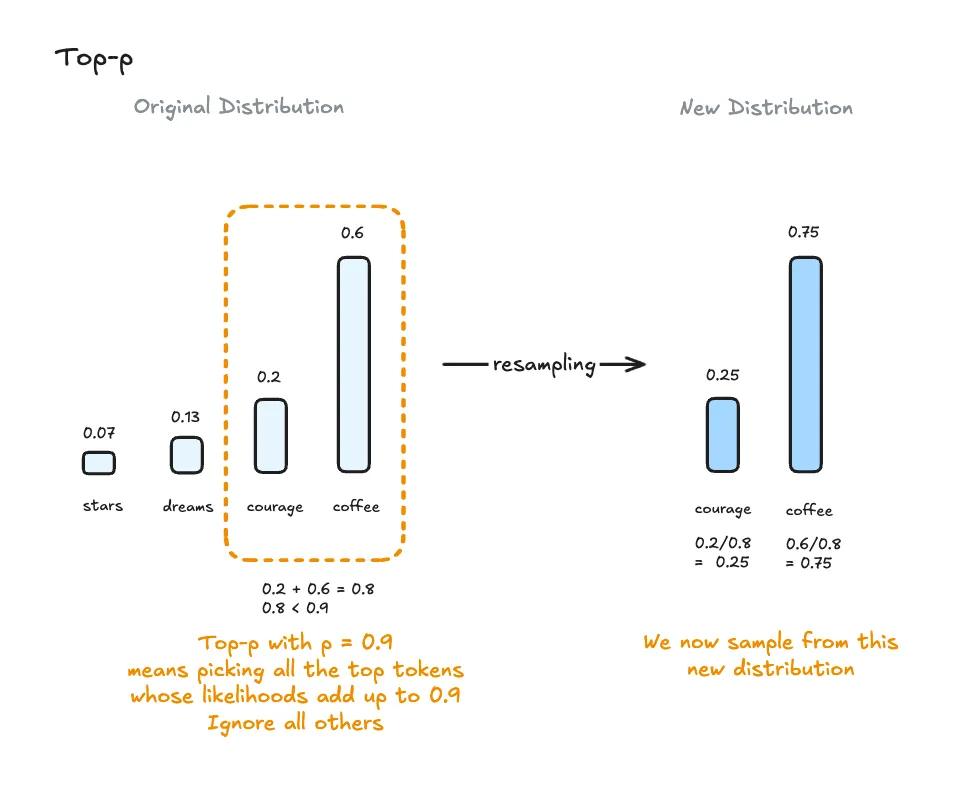
Nota: usare Top K e Top P insieme può essere ridondante, ma LM Studio permette di combinarli per raffinare il comportamento.
Structured Output
Questa opzione è disattivata. Se la attivassimo, potremmo fornire al modello uno schema JSON da rispettare rigorosamente nel formato dell’output. È utile, ad esempio, se volessimo che l’AI restituisse risposte formattate per API, documenti strutturati, o snippet con sintassi precisa. Per ora, lasciandola spenta, lasciamo il modello libero di formattare le risposte come testo naturale o codice, a seconda del prompt.
Speculative Decoding
Anche questa funzione avanzata è visibile, ma al momento non attiva. Serve a velocizzare l’inferenza usando un modello secondario più leggero (“Draft Model”) per fare previsioni preliminari. Il modello principale conferma poi se accettarle. È utile su hardware con risorse limitate per guadagnare fluidità. Per abilitarlo dovremmo prima scegliere un modello compatibile nella lista a discesa.
Tab Program
Qui possiamo ampliare le funzionalità del modello collegando moduli avanzati o “estensioni” locali, proprio come se stessimo installando app aggiuntive in un sistema operativo. Qui è possibile collegare plugin personalizzati, connettere MCP servers (Model Control Protocol), ovvero server esterni o servizi locali che interagiscono con il modello. Sarà possibile inoltre abilitare funzionalità avanzate come esecuzione di codice, recupero di documenti, ecc. In sostanza, stiamo parlando della modularità di LM Studio, cioè la possibilità di trasformarlo da semplice chatbot in una piattaforma AI interattiva ed espandibile. Questa versione presenta già installate:
js-code-sandbox: che è un plugin che permette al modello di eseguire codice JavaScript in sandbox (ambiente isolato e sicuro).
rag-v1: Plugin per RAG (Retrieval-Augmented Generation) che permette al modello di consultare documenti, appunti, PDF o database locali. Se utilizzato bene, il modello potrà rispondere basandosi su fonti reali e aggiornabili.
Anche chi non ha una formazione tecnica, a questo punto, starà probabilmente iniziando a sentire un certo entusiasmo crescere. A questo punto, forse qualcuno di voi si starà chiedendo: ‘Ma quante cose posso davvero inventare qui dentro? Se l’hai pensato, allora congratulazioni: sei un nerd consapevole.
O forse… ancora non sai di esserlo.
Scoperchiamo il vaso di Pandora
Spostiamoci sulla colonna di sinistra, clicchiamo sull’iconcina a forma di lente d’ingrandimento e… meraviglia! La lista dei modelli disponibili per LM Studio! Buon divertimento!
Se l’articolo ti è piaciuto possiamo restare in contatto su linkedin a https://www.linkedin.com/in/andreatonin/
LLMStudio #AIoffline #OpenSourceAI #ModelliLinguistici #PrivacyDigitale #IntelligenzaArtificiale #NerdCulture #AutonomiaTecnologica #AIperTutti #TecnologiaEtica

Nerd per passione e per professione da oltre 30 anni, lavoro nel mondo dell’innovazione tecnologica come CTO e consulente, progettando ecosistemi software complessi e scalabili. Parallelamente mi dedico alla formazione informatica, condividendo esperienze e buone pratiche maturate sul campo.
Scopri di più sulla mia attività di consulenza su lucedigitale.com Mi trovi anche su LinkedIn

 By
By