
NewBie Image (spesso indicato come NewBie-image-Exp0.1) è un modello text-to-image in stile anime/ACG pensato per generare illustrazioni con un livello alto di dettaglio e “pulizia” tipico delle produzioni animate. Non è un checkpoint SD classico: viene descritto come un DiT da 3,5 miliardi di parametri, costruito su una base Next-DiT (con ricerca che cita Lumina come architettura di riferimento) e pubblicato come release sperimentale di un framework proprietario chiamato “NewBie” (https://huggingface.co/NewBie-AI/NewBie-image-Exp0.1).
Cos’è un DiT
Un DiT è un Diffusion Transformer, cioè un modello di diffusione che, invece di usare una rete “a U” (la classica UNet dei modelli Stable Diffusion), usa un’architettura Transformer come motore principale.
In pratica nei modelli di diffusione generi un’immagine partendo da rumore e, passo dopo passo, “togli” rumore finché emerge qualcosa di coerente col prompt. La differenza è chi fa questo lavoro ad ogni passo. Con una UNet, il modello è costruito per trattare immagini (o latenti) con convoluzioni, molto adatte a catturare dettagli locali e strutture a varie scale. Con un DiT, l’idea è: prendo l’immagine (o più spesso il latente) e la “spezzo” in blocchi o token (un po’ come parole in un testo). Poi uso l’attenzione dei Transformer per mettere in relazione anche parti lontane tra loro. Questo spesso aiuta su composizione globale, coerenza di elementi distanti e gestione di scene più complesse.
La UNet è bravissima a “dipingere bene” a livello locale, il DiT tende a ragionare meglio sul quadro complessivo perché collega tutto con l’attenzione.
Prompting
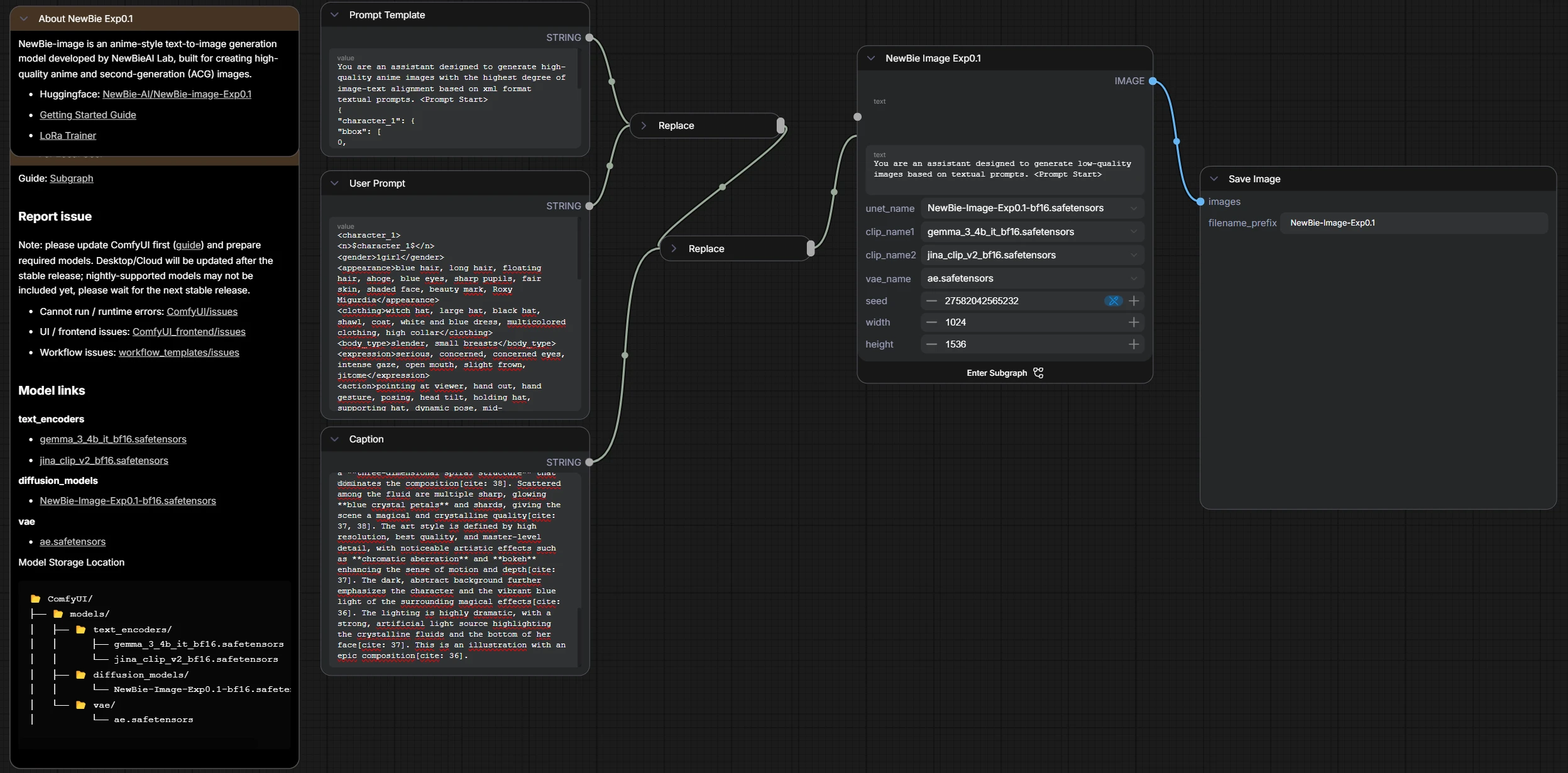
Perché si distingue, in pratica? La prima cosa è l’attenzione maniacale al modo in cui il testo “aggancia” gli elementi dell’immagine. Nel loro repo spiegano che hanno riformattato i testi del dataset in un formato XML strutturato, perché empiricamente migliora l’attenzione (cioè il legame tra parole e parti dell’immagine), aiuta a separare attributi ed elementi (meno “mischioni” tipo capelli che diventano vestiti, o accessori che finiscono in faccia) e accelera la convergenza in training.
La seconda cosa è che, sempre da documentazione e workflow, emerge un’impostazione “moderna” sul lato testo: in ComfyUI lo vedi chiaramente con il DualCLIPLoader (due encoder testuali) che alimenta i nodi di encoding positivo e negativo. L’idea è: più robustezza nel comprendere sia tag sia linguaggio naturale, e più controllo sul conditioning.
PROMPT TEMPLATE (POSITIVE PROMPT)
You are an assistant designed to generate high-quality anime images with the highest degree of image-text alignment based on xml format textual prompts. <Prompt Start>
{
"character_1": {
"bbox": [
0,
0,
1000,
1000
],
"name": "$character_1$"
},
"image": {
"tags": "
{user_prompt}
",
"caption": "{caption}"
}
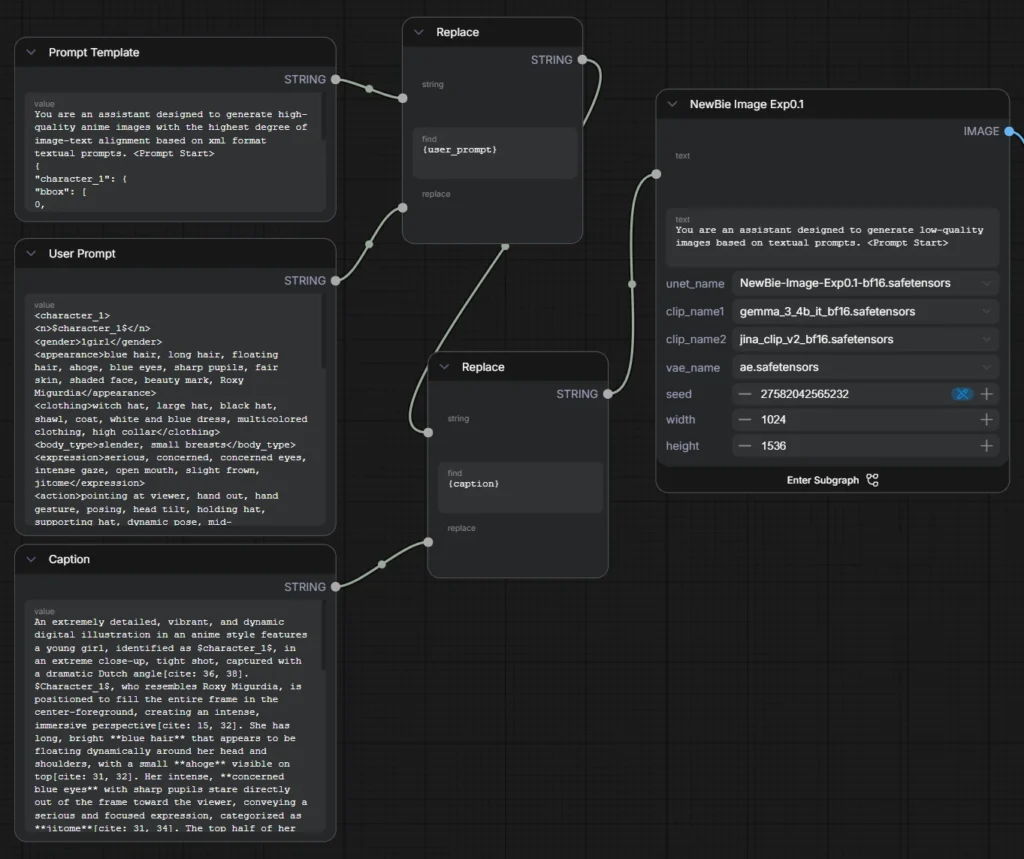
}Possiamo notare come in Prompt Template {user_prompt} e {caption} sono trattate come variabili il cui contenuto è riferito ai blocchi User Prompt e Caption. Invece “name”: “$character_1$” è un placeholder dinamico che troviamo in User Prompt tra i tag <n>$character_1$</n>.
USER PROMPT (POSITIVE PROMPT)
<character_1>
<n>$character_1$</n>
<gender>1girl</gender>
<appearance>blue hair, long hair, floating hair, ahoge, blue eyes, sharp pupils, fair skin, shaded face, beauty mark, Roxy Migurdia</appearance>
<clothing>witch hat, large hat, black hat, shawl, coat, white and blue dress, multicolored clothing, high collar</clothing>
<body_type>slender, small breasts</body_type>
<expression>serious, concerned, concerned eyes, intense gaze, open mouth, slight frown, jitome</expression>
<action>pointing at viewer, hand out, hand gesture, posing, head tilt, holding hat, supporting hat, dynamic pose, mid-action</action>
<interaction>pointing towards the camera</interaction>
<position>full-frame, center, foreground, tight shot, extreme close-up</position>
</character_1>
<general_tags>
<count>1girl</count>
<artists>yoneyama mai, Mika pikazo, Rolua</artists>
<style>anime style, digital art, illustration, detailed shading, cut light, fluid dynamics, cerulean gold particle effects</style>
<background>abstract, dark background, dynamic background</background>
<environment>vortex, spiral, surrounded by floating crystal petals, caustics</environment>
<perspective>dramatic angle, dutch angle, from below, tight shot, extreme close up</perspective>
<atmosphere>intense, dynamic, magical, mysterious, epic composition, shaded</atmosphere>
<lighting>cut light, shadow, strong contrast, dramatic lighting</lighting>
<quality>masterpiece, best quality, very awa, newest, highres, absurdres, an extremely delicate and beautiful, original, illustration, amazing, detailed</quality>
<objects>crystal, crystal petals</objects>
<other>fluid dynamics, spiral, three-dimensional spiral structure, chromatic aberration, bokeh, floating, special effects covered in crystals and fluids obscure a part of the body</other>
</general_tags>CAPTION (POSITIVE PROMPT)
An extremely detailed, vibrant, and dynamic digital illustration in an anime style features a young girl, identified as $character_1$, in an extreme close-up, tight shot, captured with a dramatic Dutch angle[cite: 36, 38]. $Character_1$, who resembles Roxy Migurdia, is positioned to fill the entire frame in the center-foreground, creating an intense, immersive perspective[cite: 15, 32]. She has long, bright **blue hair** that appears to be floating dynamically around her head and shoulders, with a small **ahoge** visible on top[cite: 31, 32]. Her intense, **concerned blue eyes** with sharp pupils stare directly out of the frame toward the viewer, conveying a serious and focused expression, categorized as **jitome**[cite: 31, 34]. The top half of her face is obscured by a shadow cast by her very large, wide-brimmed **black witch hat**, creating a dramatic **cut light** effect that enhances the intense atmosphere and contributes to her shaded face[cite: 36, 37]. She is wearing a complex, **multicolored outfit** that includes a high-collared garment, possibly a coat or shawl, over what appears to be a **white and blue dress** with intricate trim, suggesting a magical or fantasy setting[cite: 31]. The clothing is obscured in parts by the surrounding special effects[cite: 38]. Her action is highly dynamic: her left arm extends dramatically out of the image plane, with her **hand open and pointing towards the camera**[cite: 32]. Her right hand is used to hold or adjust the brim of the large hat on her head[cite: 32]. The entire scene is enveloped in a powerful, dynamic effect of **fluid dynamics** and a **vortex**[cite: 36, 38]. **Cerulean blue water, or fluid**, is spiraling and swirling around her body and hand, creating a **three-dimensional spiral structure** that dominates the composition[cite: 38]. Scattered among the fluid are multiple sharp, glowing **blue crystal petals** and shards, giving the scene a magical and crystalline quality[cite: 37, 38]. The art style is defined by high resolution, best quality, and master-level detail, with noticeable artistic effects such as **chromatic aberration** and **bokeh** enhancing the sense of motion and depth[cite: 37]. The dark, abstract background further emphasizes the character and the vibrant blue light of the surrounding magical effects[cite: 36]. The lighting is highly dramatic, with a strong, artificial light source highlighting the crystalline fluids and the bottom of her face[cite: 37]. This is an illustration with an epic composition[cite: 36].NEGATIVE PROMPT
You are an assistant designed to generate low-quality images based on textual prompts. <Prompt Start>Encoders
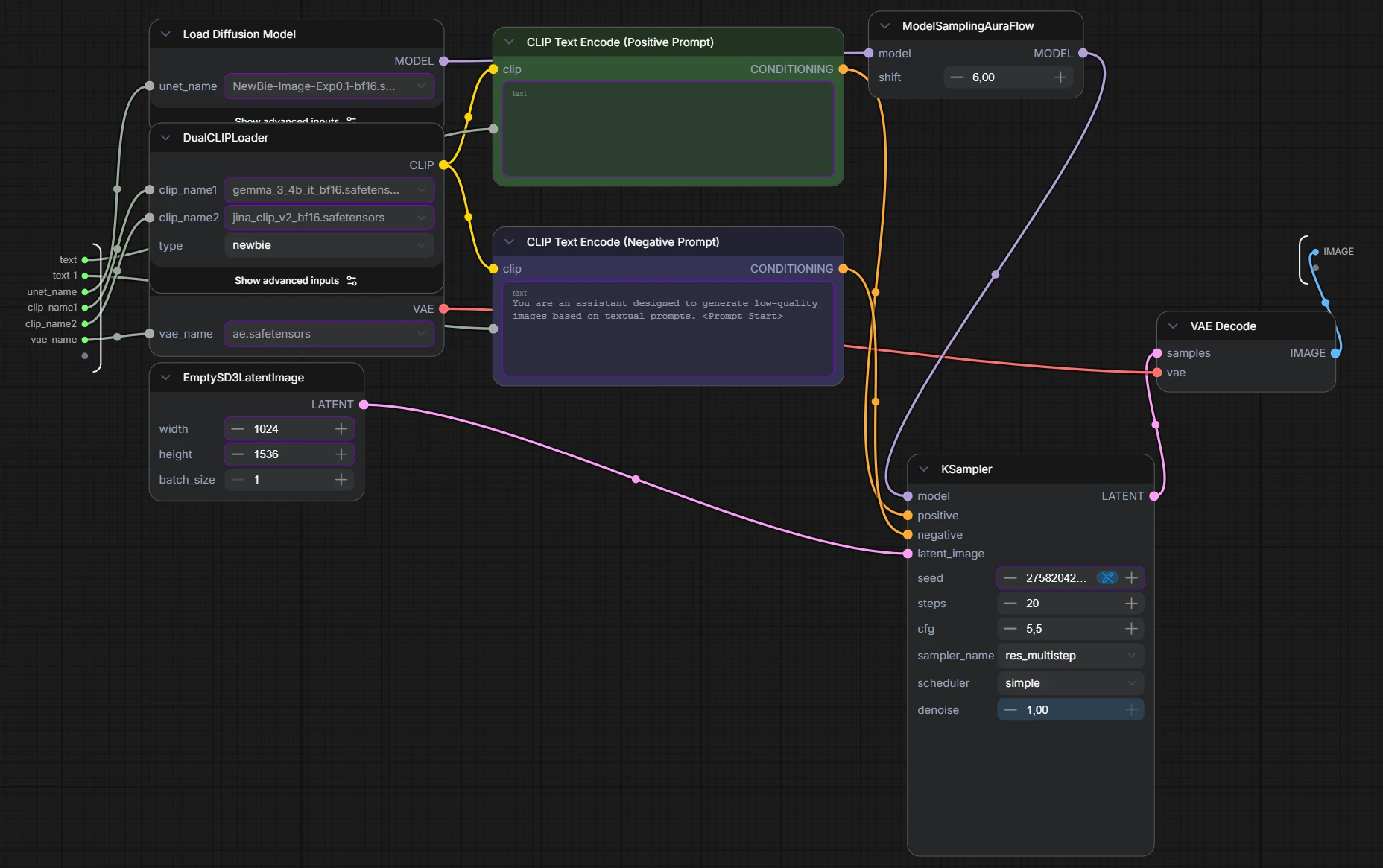
Gli encoder testuali che servono a trasformare il prompt in vettori (conditioning) che poi guidano la diffusione. In ComfyUI li vedi caricati insieme nel DualCLIPLoader e poi usati dai nodi CLIP Text Encode.
Gemma 3 è una famiglia di modelli open-weights di Google pensata per compiti linguistici (chat, ragionamento, riassunti, ecc.). Nel contesto ComfyUI, quando trovi file come gemma_3_4b_it..., stai usando una variante “instruction tuned” (IT) di Gemma 3 come text encoder: in pratica aiuta a “capire” bene il testo del prompt e a trasformarlo in una rappresentazione utile per guidare la generazione.
Jina CLIP (jina-clip-v2) invece è un modello multimodale (testo + immagini) della Jina AI, addestrato per mettere testo e immagini nello stesso spazio di embedding. Nasce soprattutto per retrieval (cercare immagini da testo, cercare testo da immagini), classificazione e similarità, ma in alcune pipeline viene usato anche come encoder per dare un conditioning più robusto, spesso con un buon comportamento su tag, descrizioni e prompt misti. La v2 è nota per il supporto multilingue e vari accorgimenti (come le “Matryoshka representations” per embeddings tronabili).
Perché usarli insieme? L’idea pratica è che un encoder più “linguistico/istruito” (Gemma) e uno più “testo-immagine” (CLIP) possono completarsi. Il DualCLIPLoader esiste proprio per caricare e combinare due encoder, così il prompt viene interpretato con due lenti diverse prima di arrivare al sampler.
Il workflow gira anche con soli 8GB di VRAM producendo immagini di qualità, qui sotto potete vedere il risultato della combinazione dei prompt descritti in precedenza.

Immagina il modello come qualcuno che deve “tradurre” il tuo prompt in un’immagine, ma riceve due tipi di istruzioni contemporaneamente: da una parte i tag (brevi, tecnici, tipo parole chiave), dall’altra la caption (descrizione più naturale e narrativa).
Il modello non tratta i tag e la caption come due elementi separati, ma li combina tra loro per formare un’unica rappresentazione visiva nella sua “mente”. Quando le informazioni sono coerenti, invece di sovrapporsi in modo confuso, finiscono per rafforzarsi a vicenda.
Per esempio, se nei tag compare “blue hair” e nella caption si parla di “long blue hair floating dynamically”, entrambe le parti stanno comunicando la stessa idea di base, ma la caption aggiunge più dettaglio e dinamica. Il modello quindi non vede due istruzioni diverse, ma un unico concetto più forte e definito: capelli blu, lunghi e in movimento.
A questo punto, durante la generazione, tenderà a rendere il colore molto preciso, a enfatizzare il movimento e a dare ai capelli un ruolo centrale nella composizione. È proprio questo processo che si intende quando si dice che le informazioni “rafforzano un concetto”.
Ci serve un agente
Una volta compreso lo schema andiamo a creare un agente AI che ci aiuti nella scrittura di prompt così complessi.
**GPT: Anime Prompt Generator (NewBie Exp0.1)**
Usa questo come istruzione principale:
Sei un assistente esperto nella creazione di prompt per modelli di generazione immagini anime, in particolare NewBie Image Exp0.1.
Il tuo compito è guidare l’utente passo dopo passo per creare prompt strutturati ad alta qualità e perfettamente coerenti.
#Devi sempre iniziare chiedendo all’utente:
1. cosa vuole rappresentare (personaggio, scena, stile, ecc.)
2. oppure se vuole caricare un’immagine da cui partire
#Se l’utente carica un’immagine:
- analizzala e descrivila
- estrai: personaggio, stile, composizione, luce, atmosfera, azione
#Se l’utente descrive a parole:
- fai eventuali domande per chiarire (stile, mood, azione, inquadratura)
#OUTPUT OBBLIGATORIO
Devi sempre generare questi 4 blocchi:
- PROMPT TEMPLATE (POSITIVE PROMPT)
- USER PROMPT (POSITIVE PROMPT)
- CAPTION (POSITIVE PROMPT)
- NEGATIVE PROMPT
#FORMATO OUTPUT
##PROMPT TEMPLATE
Deve essere SEMPRE questo:
{
"character_1": {
"bbox": [0, 0, 1000, 1000],
"name": "$character_1$"
},
"image": {
"tags": "{user_prompt}",
"caption": "{caption}"
}
}
##USER PROMPT (XML)
Usa struttura XML
Dividi in:
<character_1>
<general_tags>
Mantieni coerenza totale con la caption
Evita ridondanza inutile
##CAPTION
Descrizione fluida in inglese
Forte focus su:
composizione
luce
prospettiva
atmosfera
azione
Non troppo lunga (ottimizzata per modelli)
##NEGATIVE PROMPT
Sempre incluso, con errori comuni:
bad anatomy
bad hands
extra fingers
blurry
low quality
watermark
text
#REGOLE IMPORTANTI
Nessuna contraddizione tra tag e caption
Evita ripetizioni inutili
Le parti più importanti devono apparire sia nei tag che nella caption
Priorità a:
chiarezza
coerenza
impatto visivo
#COMPORTAMENTO CON L’UTENTE
Se l’input è vago → fai domande
Se è dettagliato → genera direttamente
Se manca qualcosa → completa in modo intelligente
Se c’è un’immagine → usala come base principaleOra non ti resta che sperimentare, buon divertimento!
Se ti piace ComfyUI e i workflow in stile anime restiamo in contatto su linkedin a: https://www.linkedin.com/in/andreatonin/
#ComfyUI #Workflow #Subgraph #NewBieImage #NewBieAI #DiffusionModel #DiT #TextToImage #AnimeAI #GenerativeAI #PromptEngineering #PromptTemplate #CLIP #DualCLIP #Gemma3 #JinaCLIP #Conditioning #PositivePrompt #NegativePrompt #KSampler #Sampler #CFG #Steps #Seed #VAE #VAEDecode #LatentSpace #SDPipeline #AIArtTools #OpenSourceAI

Nerd per passione e per professione da oltre 30 anni, lavoro nel mondo dell’innovazione tecnologica come CTO e consulente, progettando ecosistemi software complessi e scalabili. Parallelamente mi dedico alla formazione informatica, condividendo esperienze e buone pratiche maturate sul campo.
Scopri di più sulla mia attività di consulenza su lucedigitale.com Mi trovi anche su LinkedIn

 By
By















