Quando si parla di “OpenPose” in giro per ComfyUI, spesso si intende una cosa molto concreta: prendere una foto, riconoscere la postura del soggetto (testa, busto, braccia, mani, gambe, piedi, a volte anche i tratti del viso) e trasformarla in una mappa di pose che poi puoi riusare come guida. È quella silhouette fatta di “ossicini” e punti che avrai visto mille volte nei workflow: non è un effetto grafico, è un modo per tradurre un’immagine in una struttura.
Che cos’è OpenPose
OpenPose nasce come progetto di computer vision per stimare la posa umana in 2D, anche con più persone nella stessa scena. L’idea chiave è che un algoritmo può imparare a trovare “punti di interesse” coerenti (spalle, gomiti, polsi, anche, ginocchia…) e poi collegarli nel modo giusto. La parte che lo rende potente non è solo “trovare punti”, ma capire quali punti appartengono alla stessa persona quando nell’immagine ci sono più corpi o arti sovrapposti.
Storicamente, la tecnologia che ha reso OpenPose famoso (in ambito ricerca) ha reso popolare un approccio in due pezzi: da una parte mappe di confidenza che dicono “qui c’è probabilmente un gomito”, dall’altra mappe di collegamento tra parti (quelle che spesso trovi citate come affinità tra parti) che aiutano a ricostruire lo scheletro corretto. In pratica: non basta vedere un polso, bisogna capire a quale braccio appartiene.
Perché funziona? Perché riduce la complessità dell’immagine a una rappresentazione molto più stabile. Luci, texture, vestiti, sfondo: tutto sparisce. Rimane la geometria del corpo. E la geometria è una guida fortissima quando vuoi controllare posizione, gesto, dinamica, equilibrio della figura. È il motivo per cui, anche quando cambi stile o soggetto, la posa resta leggibile e replicabile.
Evoluzioni
OpenPose nasce da un percorso lungo di ricerca sulla stima della posa e, una volta rilasciato, è cresciuto per passi successivi: prima ha imparato a riconoscere i punti chiave del corpo, poi ha esteso la lettura al volto e alle mani, mentre in parallelo venivano migliorate compatibilità e robustezza (per esempio su Windows, con immagini di formati diversi e con sorgenti come le IP camera). Col tempo il focus si è spostato anche sulle prestazioni, con aumenti importanti di velocità e funzioni come il tracciamento del soggetto, fino ad arrivare a scenari più avanzati come l’uso multi-camera e il 3D in modalità asincrona. Gli aggiornamenti più recenti hanno consolidato l’integrazione tecnica (CUDA, cuDNN e API Python), rendendo la tecnologia più facile da usare e più spendibile in applicazioni reali come analisi sportiva e monitoraggio in ambito sanitario.
Dal laboratorio a Comfy UI
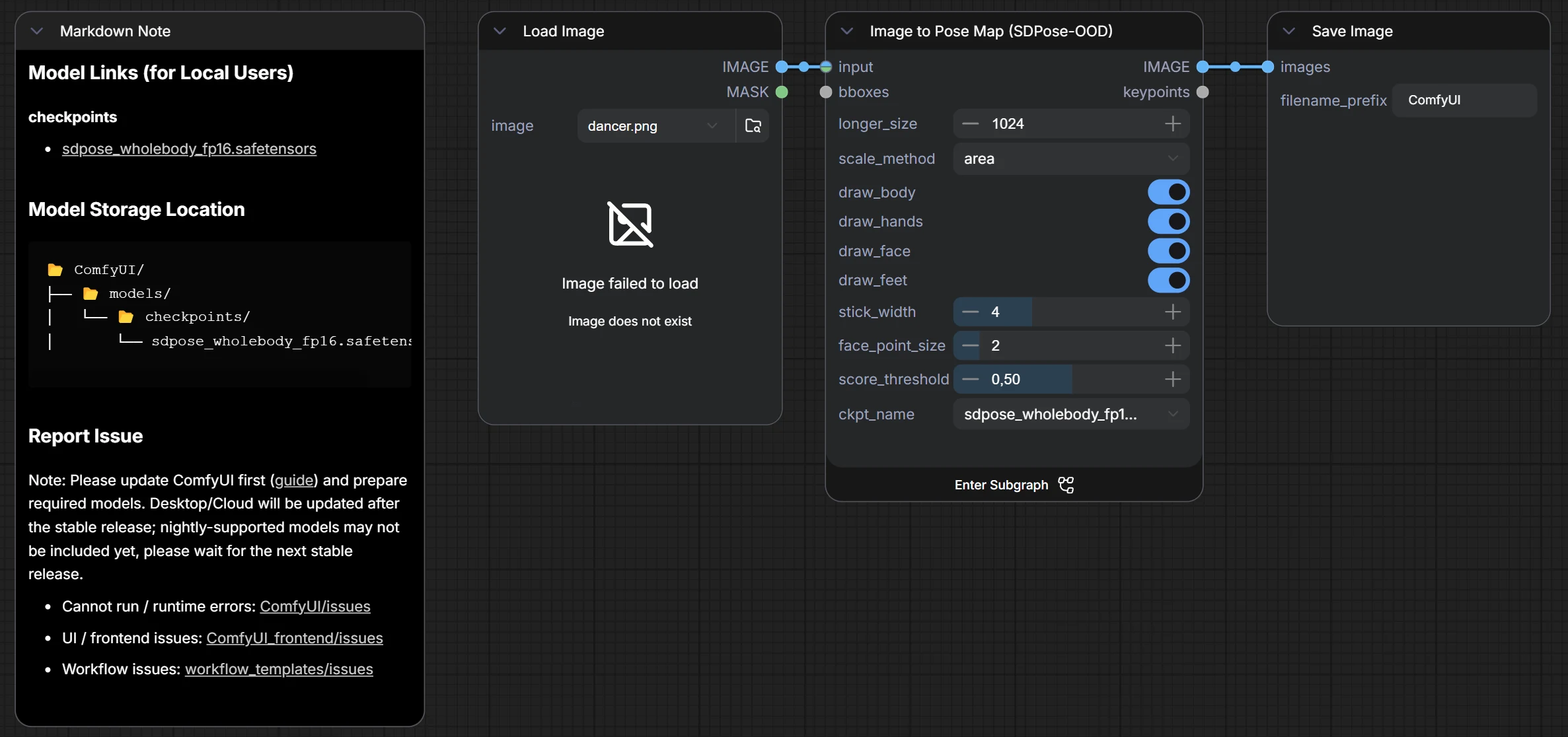
In ComfyUI non stai “usando OpenPose” come nel paper originale, stai usando la stessa idea (pose estimation) tramite nodi che fanno estrazione di keypoints e generazione di una pose map. Nel tuo caso si vede chiaramente che stai usando un modello chiamato SDPose wholebody (sdpose_wholebody_fp16.safetensors), quindi una variante pensata per estrarre un set di punti esteso (corpo + mani + volto + piedi) e produrre un’immagine di output che rappresenta la posa.
Questo workflow non “crea immagini belle” ma produce un intermedio tecnico (la pose map) che poi userai altrove come controllo. Se lo guardi con questa lente, ogni nodo inizia ad avere senso.
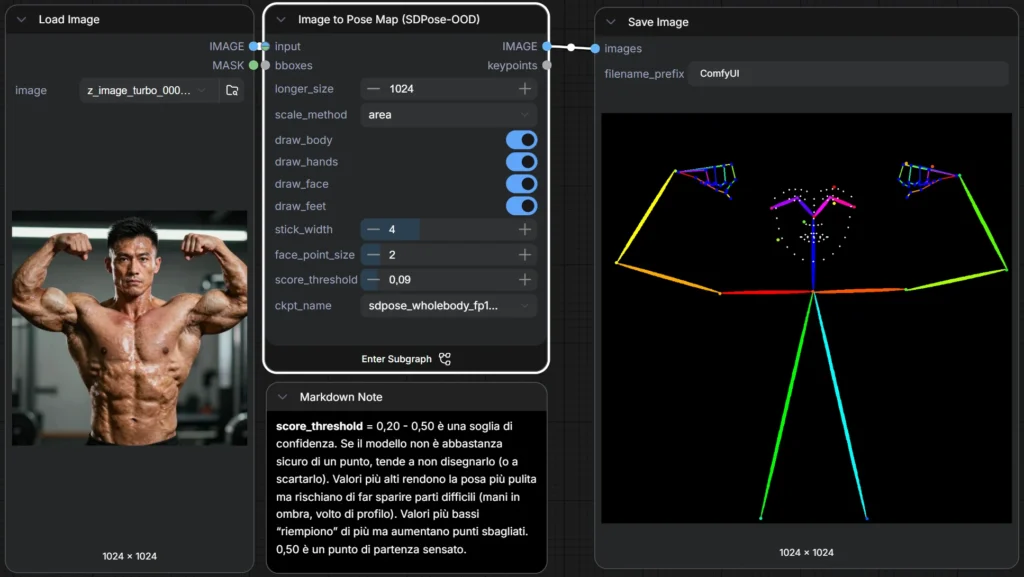
Nella prima schermata il flusso è volutamente diretto: carichi un’immagine, la trasformi in pose map, salvi il risultato. Il nodo centrale è Image to Pose Map (SDPose-OOD). In pratica è il modo più rapido per fare quello che vuoi, infatti prende l’immagine in ingresso e restituisce un’immagine di pose map, con opzioni per decidere cosa disegnare e come.
L’opzione longer_size = 1024 serve a ridimensionare l’immagine internamente prima dell’estrazione, mantenendo le proporzioni, portando il lato più lungo a 1024 pixel. Non è “qualità” in senso estetico: è una scelta che influenza quanto bene il modello vede dettagli piccoli come mani e viso. Se lavori con immagini troppo piccole, le dita diventano rumore; se lavori con immagini enormi, sprechi tempo e a volte non migliori davvero.
scale_method = area è il metodo di ridimensionamento. Per iniziare va benissimo lasciarlo così: evita artefatti strani ed è una scelta “safe”.
I toggle draw_body, draw_hands, draw_face, draw_feet sono esattamente quello che sembrano, non cambiano solo “cosa vedi”, cambiano l’utilità della pose map. Se vuoi controllare una danza o un gesto ampio, il corpo basta. Se vuoi mani leggibili (gesti, dita, oggetti), attiva le mani. Se vuoi espressione o direzione dello sguardo (quando supportato bene), attiva il volto. I piedi sono utili quando la posa coinvolge appoggi, passi, salti.
stick_width = 4 e face_point_size = 2 sono parametri grafici: quanto spesse le linee dello scheletro e quanto grandi i punti del viso. Non cambiano la “verità” dei keypoint, ma cambiano quanto la mappa risultante è leggibile e quanto è facile da usare come controllo in altri passaggi.
score_threshold = 0,50 è una soglia di confidenza. Se il modello non è abbastanza sicuro di un punto, tende a non disegnarlo (o a scartarlo). Valori più alti rendono la posa più pulita ma rischiano di far sparire parti difficili (mani in ombra, volto di profilo). Valori più bassi “riempiono” di più ma aumentano punti sbagliati. 0,50 è un punto di partenza sensato.
Sulla destra si vede che il nodo produce anche un output chiamato keypoints (oltre all’immagine). È un dato strutturato, utile se vuoi riusare i keypoint in modo più “programmabile” nel workflow.
Il nodo Save Image salva l’immagine risultante. Il filename_prefix è ComfyUI, quindi ti ritroverai un file con quel prefisso nella cartella di output.
Keypoints
I keypoints sono un dato “strutturato” (solitamente JSON), non un’immagine. In pratica sono un insieme di coordinate (quasi sempre x, y in pixel, a volte anche una confidence per ogni punto) che descrivono dove il modello ha trovato parti del corpo, spalle, gomiti, polsi, anche, ginocchia, caviglie e, con i modelli “wholebody”, anche punti di mani, volto e piedi. Spesso includono anche l’informazione su quali punti sono collegati (lo scheletro), oppure quella connessione è implicita perché lo schema dei punti è fisso. Qui sotto possiamo vedere l’immagine di posa e il rispettivo codice JSON che la rappresenta.
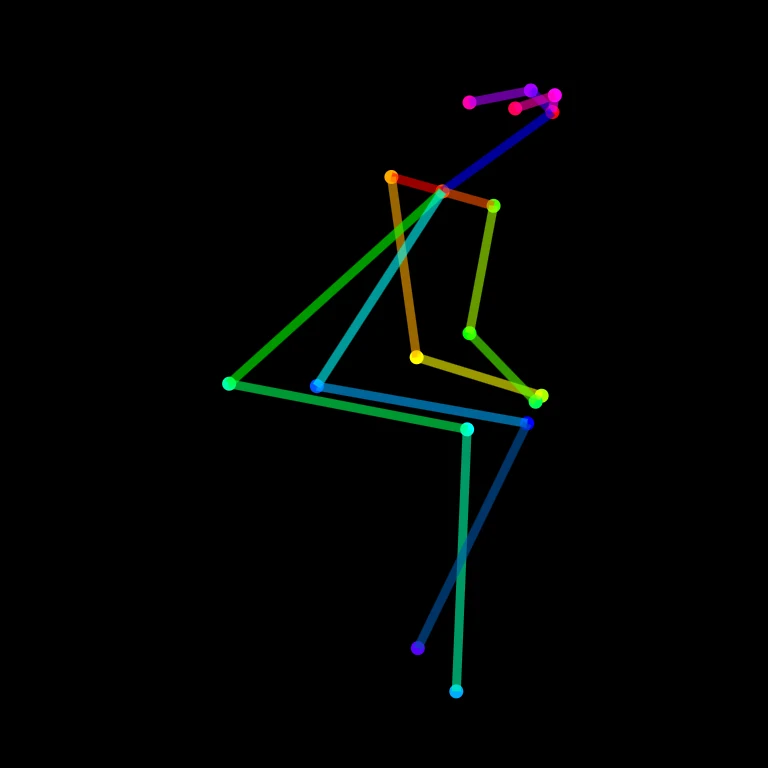
[
{
"people": [
{
"pose_keypoints_2d": [552.450621752689, 112.078854578858, 1, 442.476498629587, 191.404451585685, 1, 391.39562176913, 176.981615766262, 1, 416.635584453121, 357.267063509052, 1, 541.633494888122, 395.727959027514, 1, 493.557375490045, 205.827287405108, 1, 469.519315791006, 333.229003810013, 1, 535.623979963362, 401.737473952274, 1, 229.138718800619, 383.708929177995, 1, 467.115509821102, 429.381242606168, 1, 456.298382956535, 691.396093325689, 1, 316.87763670211, 386.112735147898, 1, 527.210659068699, 423.371727681408, 1, 417.837487438073, 648.12758586742, 1, 530.816368023555, 90.4446008497229, 1, 554.854427722593, 95.2522127895305, 1, 469.519315791006, 102.463630699242, 1, 515.191629219179, 108.473145624002, 1]
}
],
"canvas_height": 768,
"canvas_width": 768
}
]Rispetto all’immagine di posa, non è “più utile” in assoluto, è più flessibile. L’immagine di posa è comoda perché la vedi e la passi subito a nodi che si aspettano una mappa (tipo ControlNet/OpenPose o simili). I keypoints invece sono meglio quando vuoi controllo e riuso, infatti puoi ridisegnarli con stile diverso, filtrarli, trasformarli, combinarli, oppure salvarli come “dati” per riprodurre la stessa posa senza dipendere dall’immagine.
Se vuoi solo guidare una generazione, nella maggior parte dei workflow ti basta la pose map (l’immagine con omini/linee). È il percorso più semplice: estrai → disegni → usi come condizione.
Se invece vuoi lavorare in modo più “pulito”, usi i keypoints come “sorgente” e l’immagine come “renderizzazione”. Per esempio: estrai i keypoints una volta, poi li passi a un nodo come DrawKeypoints per generare varie pose map con parametri diversi (linee più spesse, soglia diversa, solo corpo senza mani) senza rifare l’estrazione ogni volta. Oppure modifichi i keypoints (anche solo spostando qualche punto) per correggere un braccio che il modello ha letto male, e poi ridisegni una pose map coerente.
Un altro uso molto concreto è quando vuoi riutilizzare una posa tra immagini diverse o tra sessioni. L’immagine di posa è già “cotta” (se cambi spessore, soglia, scaling, non recuperi l’informazione originale), mentre i keypoints restano un dato editabile. In alcuni setup puoi anche salvarli in JSON e ricaricarli, così ti costruisci una piccola libreria di pose.
Open Graph
Sbirciamo sotto al cofano, apriamo Open Graph.
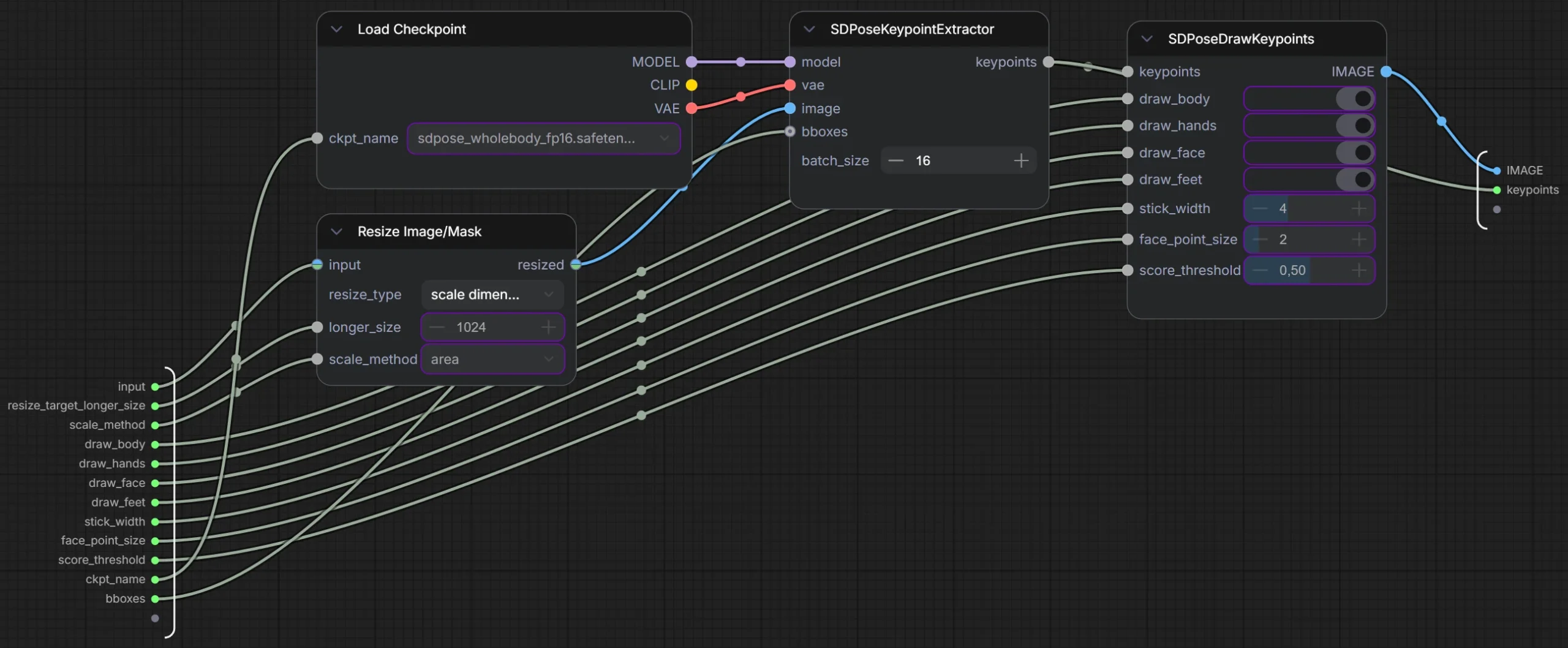
Il nodo Load Checkpoint carica sdpose_wholebody_fp16.safetensors e produce tre uscite tipiche (MODEL, CLIP, VAE). Nel tuo sottografo si vede che MODEL e VAE vengono usati dal nodo di estrazione. Questo è un dettaglio importante perché non sempre un estrattore lavora “da solo”, spesso ha bisogno di un modello e di un VAE coerenti per interpretare l’immagine nel modo atteso.
Il nodo Resize Image/Mask porta l’immagine a una dimensione gestibile e coerente, con longer_size = 1024 e scale_method = area. Qui è lo stesso principio del flusso principale, solo che lo stai facendo in modo esplicito. Questo è spesso il punto dove, quando impari, inizi a “sentire” la differenza, se ti interessa la qualità delle mani, di solito non vuoi lavorare con un input troppo piccolo.
Il nodo SDPoseKeypointExtractor è quello che fa il lavoro di computer vision vero e proprio. Prende modello/vae e immagine e tira fuori keypoints. Si vede anche batch_size = 16, che riguarda quante elaborazioni gestisce in parallelo (dipende dalla GPU e da come è implementato quel nodo). Per chi parte, la cosa più sana è non toccarlo finché non hai un motivo: se la VRAM scoppia o se vuoi ottimizzare.
Nota anche l’ingresso bboxes: vuol dire che, se vuoi, puoi dare al nodo un’indicazione su dove guardare (bounding box). Nel tuo flusso non la stai usando, quindi l’estrattore prova a trovare automaticamente la figura. È perfetto per iniziare. Più avanti, quando hai immagini con più persone o soggetti parziali, le bboxes diventano un trucco utilissimo.
Il nodo SDPoseDrawKeypoints prende i keypoint e li trasforma in un’immagine. Qui ritornano le stesse scelte del flusso principale: cosa disegnare (body/hands/face/feet), spessore delle linee, dimensione dei punti del viso, soglia di confidenza.
Strumenti di supporto
Elenchiamo, per utilità, una serie di strumenti online pratici per lavorare con OpenPose e generare pose map senza installare nulla. OpenPoseAI (https://openposeai.com/) è comodo quando vuoi costruire o rifinire pose in modo guidato, con un approccio molto “editor” e orientato al controllo della postura.
OpenPoses (https://openposes.com/) è invece una soluzione rapida per ottenere pose map pronte all’uso (ideale quando ti serve partire subito con una base e poi portarla nel tuo workflow).

Pose my Art (https://posemy.art/) permette di esportare in formato OpenPose.

Cascadeur (https://cascadeur.com/) è un tool di posa AI-driven potentissimo che supporta anche un manichino OpenPose.
Per chi si occupa abitualmente di character design, OpenPose rappresenta una risorsa strategica in grado di ottimizzare significativamente il workflow.
Se hai trovato questo articolo interessante restiamo in contatto su linkedin a: https://www.linkedin.com/in/andreatonin/
OpenPose #PoseEstimation #Keypoints #WholeBody #ComfyUI #SDPose #PoseMap #Resize #ScoreThreshold #Workflow

Nerd per passione e per professione da oltre 30 anni, lavoro nel mondo dell’innovazione tecnologica come CTO e consulente, progettando ecosistemi software complessi e scalabili. Parallelamente mi dedico alla formazione informatica, condividendo esperienze e buone pratiche maturate sul campo.
Scopri di più sulla mia attività di consulenza su lucedigitale.com Mi trovi anche su LinkedIn

 By
By