Nel mondo in rapida trasformazione della creatività digitale, l’intelligenza artificiale ha già trovato posto come strumento potente e talvolta misterioso… Ma se ti dicessi che è possibile entrare nel cuore del processo generativo, controllarlo, modificarlo e visualizzarlo passo dopo passo, come si farebbe con un circuito creativo?
Benvenuto in ComfyUI, l’interfaccia a nodi che sta rivoluzionando il modo in cui i professionisti del settore creativo interagiscono con l’AI generativa.
Cos’è ComfyUI?
ComfyUI è un’interfaccia utente basata su nodi, progettata per lavorare con modelli come Stable Diffusion in modo modulare, visuale e completamente trasparente. A differenza degli strumenti “prompt-to-image”, dove la magia avviene in una scatola nera, ComfyUI apre quella scatola e mostra ogni passaggio, ogni parametro, ogni possibilità.
Lo possiamo pensare come un software di compositing, ma per l’immaginazione computazionale.
L’interfaccia a nodi per visualizzare il pensiero creativo
L’elemento più distintivo di ComfyUI è la sua interfaccia a nodi, dove ogni componente del processo generativo, dal testo iniziale, al tipo di scheduler, al modello di base, fino all’output finale, è rappresentato da un modulo visivo.
Per chi lavora con tool come Blender o Unreal Engine, la logica è familiare, costruire significa pensare visivamente. ComfyUI applica questo paradigma alla generazione di immagini tramite AI, rendendolo non solo più controllabile, ma anche più esplorabile.
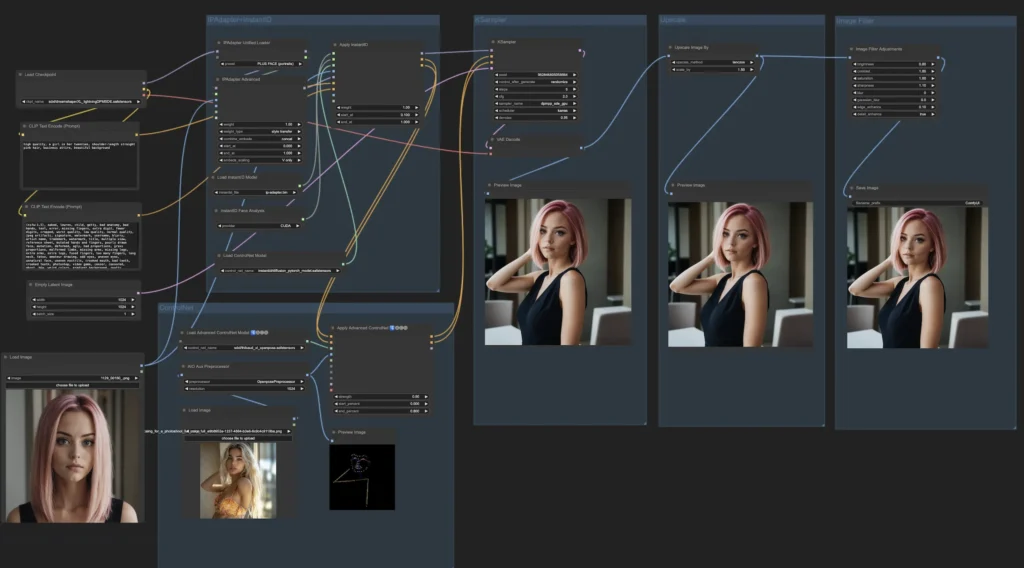
Questa immagine rappresenta un workflow visivo in ComfyUI. Il flusso è composto da moduli attraversati da dati e trasformazioni. Analizziamo un flusso “classico” in ComfyUI.
1. Moduli di partenza: caricamento risorse
- Load ControlNet Model + Apply Advanced ControlNet: integra ControlNet, una rete di controllo che guida la generazione basata su immagini, pose, depth map, ecc.
- Load Checkpoint: carica un modello Stable Diffusion specifico
- CLIP Text Encode (Prompt + Negative Prompt): codifica i prompt testuali che guidano la generazione (descrizione desiderata + elementi da evitare).
- Load Image / Empty Latent Image: forniscono immagini di riferimento o latenti vuote, utili per il controllo visivo della composizione.
In un certo senso, le operazioni descritte ricordano la fase di setup su Midjourney, quando scriviamo il prompt e carichiamo immagini di riferimento per comunicare in modo più preciso la nostra visione all’intelligenza artificiale generativa.
2. Moduli intermedi: adattamento e analisi
- IPAdapter + InstantID: moduli per l’adattamento facciale e l’identificazione dell’identità visiva. Consentono di mantenere coerenza nei tratti del volto, anche in presenza di manipolazioni.
- Face Analysis / Apply InstantID: analizzano la struttura del volto nella reference e applicano l’identità all’output generato.
- Latent Connection e Sampling: i nodi collegano le varie informazioni e passano alla fase di generazione vera e propria.
In genere, queste operazioni cerchiamo di gestirle in DALL·E attraverso prompt ben strutturati, o affidandoci a un GPT specializzato per affinare le istruzioni. In Midjourney, possiamo tentare un approccio più visivo, ad esempio con una moodboard. Tuttavia, in entrambi i casi il processo resta in gran parte una black box, il funzionamento interno dell’AI rimane invisibile all’utente, che ha un controllo limitato su ciò che avviene realmente dietro le quinte.
3. Generazione e preview
- KSampler: modulo di generazione che, usando il modello e i prompt, crea un’immagine latente.
- VAE Decode: converte l’immagine latente in formato visivo.
- Preview Image: mostra il risultato della generazione.
4. Post-processing
- Upscale Image By: aumenta la risoluzione dell’immagine usando l’algoritmo Lanczos, adatto per non perdere dettagli.
- Image Filter Adjustments: consente di applicare correzioni di immagine (luminosità, contrasto, saturazione, nitidezza, ecc.) per perfezionare l’aspetto finale.
- Save Image: salva l’output definitivo.
L’upscale di solito lo applichiamo a parte in Midjourney e gli aggiustamenti si possono gestire (blandamente) via prompt-engineering o se siamo professionisti con strumenti di post-processing come Photoshop/GIMP.
Questo flusso mette chiaramente in luce la capacità di ComfyUI di offrire un controllo profondo e modulare sull’intero processo creativo. Tutto inizia con l’inserimento di prompt testuali e immagini di riferimento, che fungono da base concettuale e visiva per la generazione. Da lì, il sistema consente di applicare trasformazioni guidate attraverso strumenti avanzati come InstantID e ControlNet, che permettono di modellare con precisione l’identità del soggetto o la struttura dell’immagine.
Il risultato è un output che non solo appare coerente e realistico, ma che può essere modificato in ogni suo aspetto, mantenendo il controllo su ogni singolo passaggio. Per un professionista del settore creativo, questo approccio rappresenta un enorme vantaggio rispetto agli strumenti “black-box”: qui le immagini non vengono semplicemente generate, ma progettate, in modo riproducibile, consapevole e altamente personalizzabile.
Va detto, però, che ComfyUI non è uno strumento per tutti.
La sua interfaccia a nodi, sebbene estremamente potente, presenta una curva di apprendimento ripida, specialmente per chi non ha familiarità con workflow visivi o pipeline modulari. Per questo motivo, potrebbe risultare poco adatto a chi ne fa un uso occasionale o a chi cerca risultati immediati con il minimo sforzo.
Come installare ComfyUI su Windows (senza impazzire)
Anche se ComfyUI può sembrare ostico a un primo sguardo, l’installazione è più semplice di quanto sembri.
Per usare ComfyUI in modo efficace ci servirà una GPU NVIDIA compatibile con CUDA (preferibilmente con almeno 8-12 GB di VRAM), diversi GB di spazio nel disco fisso e un sistema operativo compatibile Windows, Linux o macOS (con limiti)
Scarichiamo il software per Windows da qui: https://www.comfy.org/
L’eseguibile (ComfyUISetup{versione}-x64.exe) ci guiderà nella configurazione, presentando in ordine:
- La richiesta di installazionedi Python
- Il messaggio “Missing models”, che si riferisce al fatto che non trova uno o più file di modello necessari per eseguire il workflow o per far funzionare determinati nodi. ComfyUI cerca automaticamente determinati modelli predefiniti nelle sue cartelle interne (es. modelli base, LoRA, VAE, ControlNet, ecc.). Se non li trova, o se un nodo fa riferimento a un file che non esiste più, ti mostra l’errore “Missing models”. Segui le istruzioni a video per installare i file mancanti.
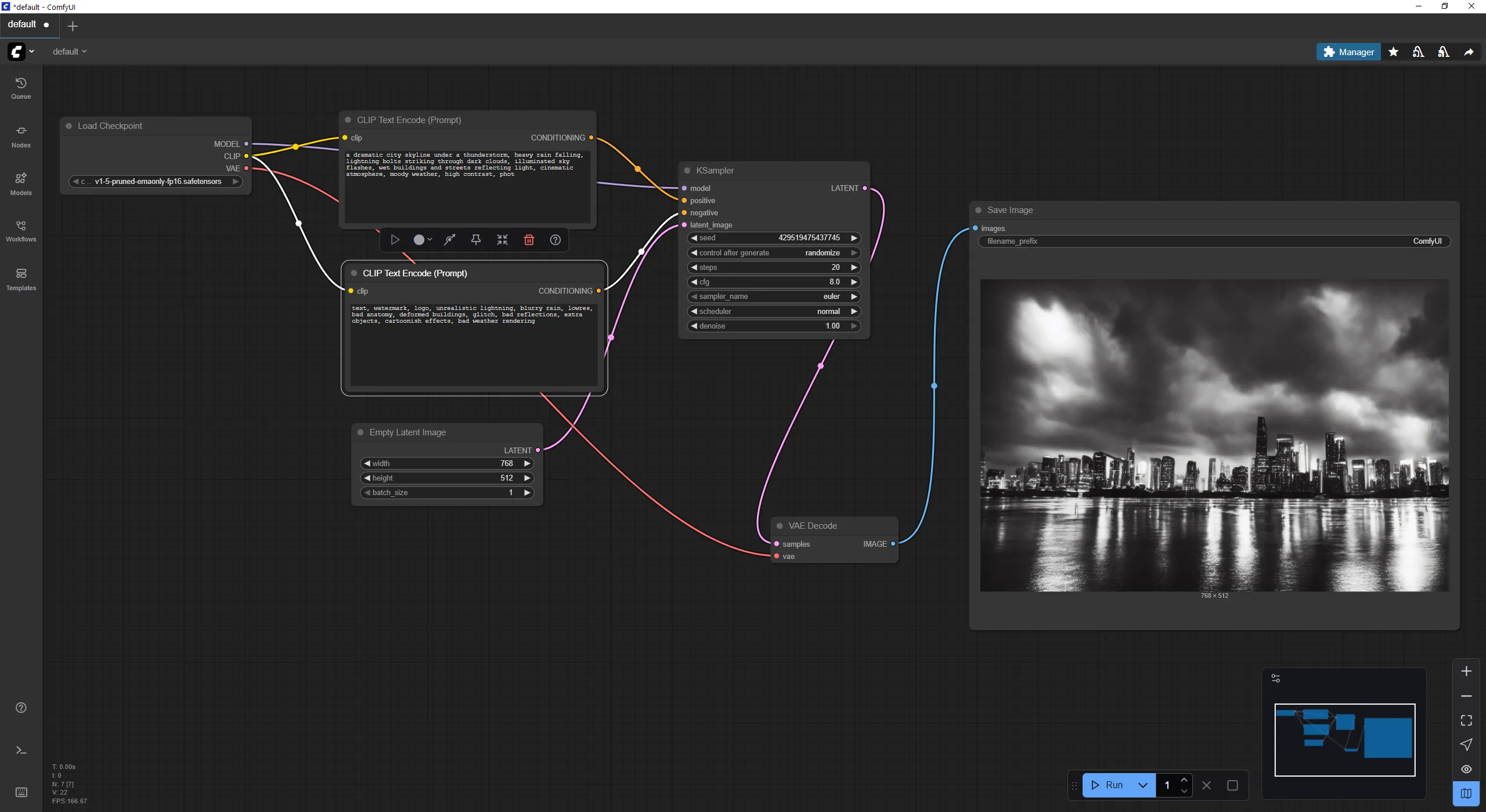
Iniziamo con un test semplice, senza troppe pretese, l’obiettivo è prendere confidenza con il flusso di lavoro. Sarà importante definire con cura sia il prompt positivo che quello negativo, per guidare correttamente la generazione ed evitare artefatti indesiderati.
POSITIVO
a dramatic city skyline under a thunderstorm, heavy rain falling, dark clouds, illuminated sky flashes, wet buildings and streets reflecting light, cinematic atmosphere, moody weather, high contrast, photorealistic, storm clouds above the skyline, dark urban aesthetic, ambient lighting, wide angle view, ultra high resolution
NEGATIVO
text, watermark, logo, unrealistic lightning, blurry rain, lowres, bad anatomy, deformed buildings, glitch, bad reflections, extra objects, cartoonish effects, bad weather renderingCopia i testi nei rispettivi box, uno va collegato all’ingresso positive del nodo KSampler, l’altro a negative.
Segui il flusso delle connessioni per verificare che tutto sia al posto giusto.
Quando il setup è completo, clicca sul pulsante Run in basso a destra per avviare la generazione…
I file grafici generati verranno salvati in: Utenti\{nomeutente}\Documenti\ComfyUI\output
Cosa contiene questo workflow
Questo flusso viene eseguito nel seguente ordine:
- Load Checkpoint: usa il modello
v1-5-pruned-emaonly-f16.safetensors, una versione ottimizzata di Stable Diffusion 1.5. - CLIP Text Encode: prompt positivi e negativi
- Empty Latent Image: imposta una tela virtuale 512×512 pixel.
- KSampler: è il nodo principale di campionamento (sampling) che prende un’immagine latente (rumore o un input già lavorato) e produce un output latente che poi viene decodificato in immagine. In pratica è il cuore del processo di generazione e decide come il rumore iniziale viene trasformato nell’immagine finale.
- VAE Decode: converte il risultato latente in immagine visiva.
- Save Image: salva l’output finale.
Nel nodo KSampler in ComfyUI trovi varie impostazioni:
- model → il modello di diffusione (es. SD 1.5, SDXL, ecc.) che userai.
- positive / negative → i testi condizionali (prompt positivi e negativi).
- latent → il punto di partenza (di solito “rumore casuale”).
- seed → il numero che controlla la casualità. Stesso seed = stesso risultato.
- steps → quanti passi di campionamento fare (più alto → più dettagli, ma anche più lento).
- cfg (Classifier Free Guidance) → quanto forte seguire il prompt. (Valori tipici: 5–8).
- sampler_name → l’algoritmo usato (es. Euler, Euler a, DPM++, Heun, ecc.). Ognuno ha un “feeling” diverso.
- scheduler → come distribuire i passi nel tempo (Karras, Normal, Exponential, ecc.).
- denoise → quanto rumore mantenere.
- 1.0 → immagine completamente nuova.
- <1.0 → usato per img2img o per modificare solo parzialmente un’immagine.
Dai, niente male come prima prova! E la cosa bella è che possiamo reiterare quanto vogliamo, senza preoccuparci di consumare crediti o incorrere in costi aggiuntivi. Possiamo sperimentare liberamente, affinare il risultato e divertirci nel processo!
Ecco una tabella chiara e completa con i moduli/modelli più popolari in ComfyUI, le funzioni, la cartella d’installazione, e dove trovarli.
| ✅ Modulo/Modello | 💡 Funzione principale | 📁 Cartella di installazione | 🌐 Dove trovarlo |
|---|---|---|---|
| Checkpoint | Modello base per generare immagini | models/checkpoints/ | CivitAI, Hugging Face |
| LoRA | Aggiunge stili, personaggi, dettagli senza cambiare il modello | models/lora/ | CivitAI |
| VAE | Migliora la decodifica dell’immagine latente | models/vae/ | Hugging Face |
| ControlNet | Guida la generazione tramite immagini (pose, depth, edge, ecc.) | models/controlnet/ | Hugging Face |
| IPAdapter | Trasferisce il volto o lo stile da una reference image | models/ipadapter/ | Hugging Face |
| CLIP Vision | Necessario per IPAdapter e InstantID | models/clip_vision/ | Hugging Face |
| Upscaler | Aumenta la risoluzione delle immagini senza perdere qualità | models/upscale_models/ | CivitAI |
| Custom Nodes / Plugin | Aggiungono nuove funzioni e nodi personalizzati | custom_nodes/ | GitHub |
| ComfyUI-Manager | Plugin per installare altri plugin/modelli direttamente dall’interfaccia | custom_nodes/ComfyUI-Manager/ | GitHub – ComfyUI-Manager |
Spero che questa introduzione a ComfyUI ti sia stata utile!
Se ti fa piacere restare in contatto o confrontarci su progetti legati all’AI generativa, mi trovi su LinkedIn: linkedin.com/in/andreatonin

Nerd per passione e per professione da oltre 30 anni, lavoro nel mondo dell’innovazione tecnologica come CTO e consulente, progettando ecosistemi software complessi e scalabili. Parallelamente mi dedico alla formazione informatica, condividendo esperienze e buone pratiche maturate sul campo.
Scopri di più sulla mia attività di consulenza su lucedigitale.com Mi trovi anche su LinkedIn

 By
By